Git basic Three Trees Workflow
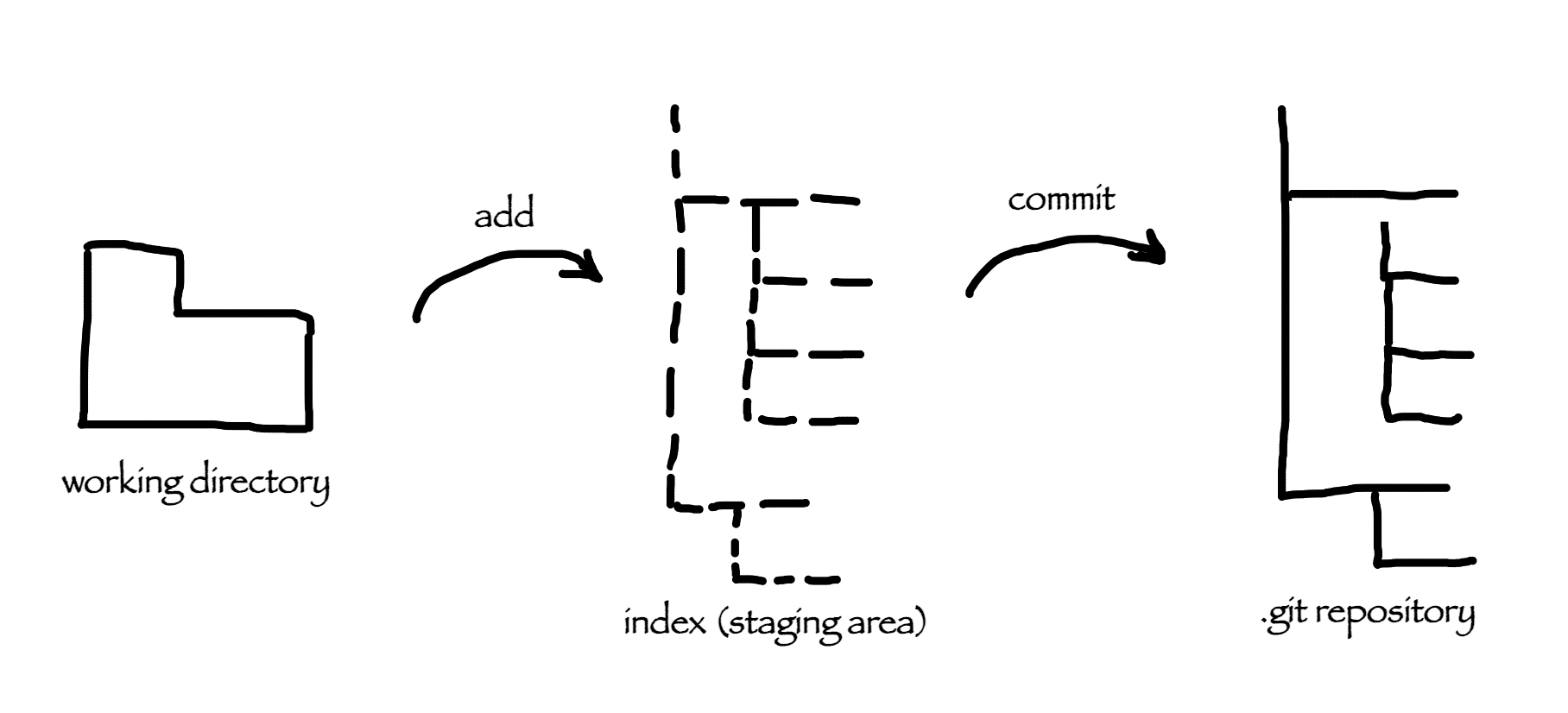
This part is important for you to grasp because everything that follows will be easier for you to understand.
There are three main parts that are maintained by git. (.git repository, Working Directory and staging area). Working Direcotry holds the actual files that we can change and that are accessible to our IDE. Working Direcotry is basically a particular version or snapshot of your project. Index or staging area (Throughout this book, I will mostly us Staging Area term, but you should know that those are the same thing) is an area where changed files are prepared to be next commit objects, you can imagine staging area as a file that git uses to keep information about changed files that will be included in your next commit. .git repository is a directory that git uses to store all files that are committed and files that are in the staging area, it is simple key-value data store, whatever you commit git will save it, create unique key for it so that you can retrieve it later.
So how these three parts are connected to one another. Let's see. When we start working on a feature we're starting from let's call it clean state - our Working Directory has same files that are tracked by git and that are present in our .git repository, and our Staging Area is clean as well, we know that because git status command will tell us "nothing to commit, working tree clean". Then when we make some change, add a new file or change existing file in our Working Directory git status will show those changed files painted in red which tell us that there is difference between files in our Working Directory and the files in the Staging Area which are files from the last commit that we made. Next, when we do git add we add those files to the Staging Area which are then ready to be committed. (Whenever you do git add command git will keep track about those changes in Index file which is placed inside .git repository). Later in this guide, I will show you how you can see all these file creations interactively using a few neat tricks in the command line). At this point, git status will tell us that we have some files ready to be committed and our Working Directory has files that are different from files in .git repository. Now to complete this circle we have to commit files that have been changed using git commit command. Once we commit them a new commit object will be created in the .git repository and again we will have a clean state between these three parts. To go a bit deeper from here after we commit changes a new commit object is created which will be a new reference that HEAD is pointing at. Now you are probably asking your self what the heck is HEAD, it is another thing that is important in the git world.
HEAD is a symbolic reference that points to the tip of the current branch that you are working on. I know it is fuzzy and probably that last sentence doesn't tell you much
so I will try to explain it in a simple way. HEAD is a reference that follows you wherever you are in your commit history, If you checkout to different branch
HEAD will follow you, you can check this out but using following command:
$ cat .git/HEAD
it will most likely give you something like this:
ref: refs/heads/master
and if you are on different branch say feature, same cat command will give you output like this:
ref: refs/heads/feature
if you reset some commit HEAD will follow you, if you make a new commit it will follow you, git uses it to know where you are currently in your commit history.
HEAD can also point directly to a commit and in this case instead of seeing this ref: refs/heads/master from the cat command above you will see something like this
7f956108475bea4c703caaa0c2a2d184904f9f2f. This means that you are in detached HEAD state.
When you are in this state any changes that you make and commit them they will not be part of any branch and what that means is that they can easily get lost unless
you have some superpower to remember hash of the commit that you've made.